2019-07-08 ~ 2019-07-29 간 진행한 내용입니다.
목차
연구배경 및 요약
벤치마크 시나리오
벤치마크 결과
분석
결론
1 - 연구배경 및 요약
ArangoDB는 Geo Index를 포함하여 다양한 Index를 지원한다.
그 중에서 다른 DB에서는 흔히 보기 어려운 Geo Index에 대해서 궁금해졌고, 위치 데이터 연산을 하는 상황에서 실제로 Geo Index가 기존에 많이 쓰이는 다른 Index와 비교해서 속도가 더 빠른지 벤치마크를 통해서 검증해보고 그에 대한 이유를 분석했다.
2 - 벤치마크 시나리오
2 - 1) 시나리오
- 매번 랜덤한 위치를 중심으로 일정범위(1km) 내 데이터를 최대 300건까지 조회하는 상황
- 배달의 민족,1km 같은 위치기반 데이팅 어플과 비슷한 경우를 가정함
- Geo Index / Hash Index / SkipList / Primary 네개의 인덱스를 비교
- 요청방식 : 1000명의 유저가 5분동안 Forever loop을 이용하여 최대한 많은 요청
- 더미데이터 : 위도 -90~90° / 경도 -180~180° 범위내의 더미데이터 60만건
2 - 2) 쿼리
FOR doc IN geo_collection FILTER GEO_DISTANCE([@lng,@lat], doc.geometry) <= 10000 LIMIT 300 RETURN doc
2 - 3) 실험환경
CPU – AMD Ryzen 5 2400G (8코어 16스레드)
Memory – 8gb
OS – Ubuntu 16.04LTS
Server - php7.0 / nginx
Clinet - Jmeter
3 - 벤치마크 결과 및 분석
3 - 1)벤치마크 결과(TPS)

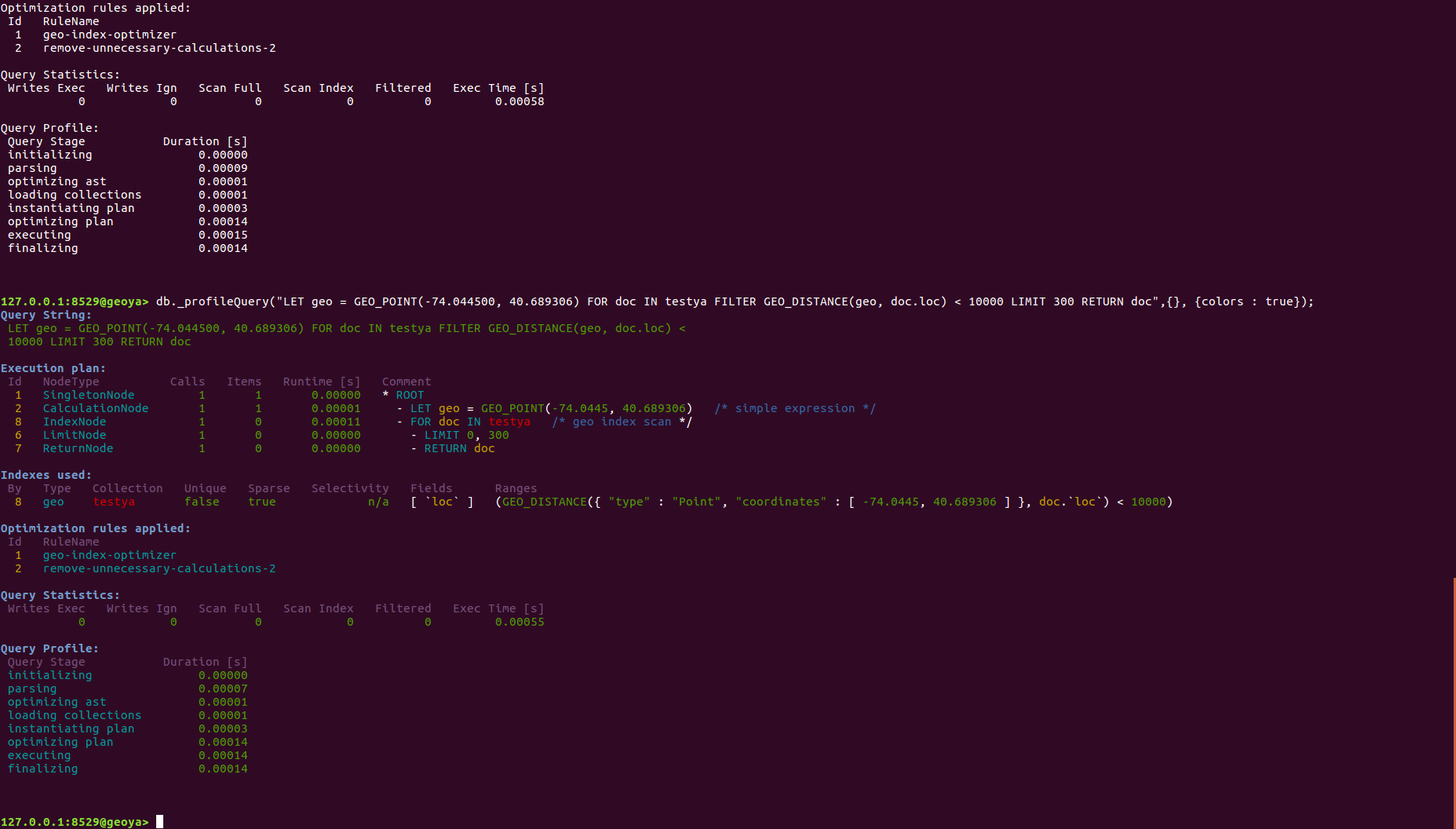
3 - 2)인덱스 사용확인(Query Profile)

4 - 분석
Geo Index가 위치데이터 연산에 특별히 빠른 이유를 자료구조에서 찾아 볼 수 있었다


ArangoDB의 GeoIndex는 쿼드트리를 사용하여 데이터를 저장하는데 쿼드 트리의 특징은 데이터를 무조건 4개의 자식노드로 분할하고 트리의 깊이를 미리 설정하면 실제 데이터의 삽입 없이도 노드의 구성을 확인 할 수 있다는 장점이 있다 또한 상위노드는 하위노드의 범위를 포함하여 보여준다

이러한 특징을 위치데이터의 연산에 사용 할 경우, 위치데이터는 위의 자료처럼 지구의 위도와 경도를 기반으로 나타내므로 값의 범위가 정해져 있다. 위도와 경도의 범위를 기반으로 쿼드트리를 이용하여 깊이를 설정해두면 미리 데이터의 섹션을 나누어 둘 수 있고, 위치를 기반으로 데이터를 조회하는 쿼리에서 상위노드에서 위치데이터의 범위를 알 수 있으므로 불필요한 노드의 검색을 줄이고 빠르게 데이터를 찾아 갈 수 있다. 실제로 ArangoDB의 GeoIndex에서 임의로 위도와 경도값을 벗어난 숫자값으로 조회를 요청했을때 허용하는 값이 아니라는 에러가 생기는걸 확인 할 수 있었다.
5 - 결론
결론적으로 Geo Index가 12~33%가량 높은 TPS를 보여주었고 그에 대한 이유를 Quad Tree 자료구조에서 찾아볼 수 있었다. Quad Tree는 위도와 경도라는 일정한 범위가 정해져 있는 데이터를 요청에 따라서 필요한 부분만 조회하는데 효율적이고, 이 연구에서 진행한 테스트 상황 외에도 3D 게임에서 필요한 지형을 빠르게 검색할때 쓰이는 지형관리 기법으로 사용되는걸 알 수 있었다.
'Server' 카테고리의 다른 글
| Process와 Thread (0) | 2022.04.04 |
|---|---|
| Cookie / Session - sticky session / session clustering (0) | 2022.02.12 |
| docker compose 외부네트워크 설정 (0) | 2021.10.06 |
| nginx - react - springboot 환경에서 cors이슈해결기록 (0) | 2021.05.20 |
| 웹서버 비동기 방식과 동기 방식의 차이점, 장단점, 특징 (0) | 2018.08.16 |